If you have been trying to get sinkom running and hit a wall, devices dropping packets, automations triggering but not completing, or a dashboard that reset itself for no apparent reason. You are not doing something wrong. You are just missing the information that every tutorial deliberately skips. The marketing materials show a unified, intelligent ecosystem where devices communicate automatically and the AI handles everything. What they do not show is the three-hour mark, when your edge devices stop talking to the cloud server and your logs fill up with timeout errors.
Every competing article on this topic was written by someone who read the documentation but never touched a deployment. They describe sinkom the way a brochure describes a car. Nobody tells you what happens when you turn the key.
The first time I set up sinkom, I spent about forty minutes connecting integrations and building three automations before I noticed the trigger log was showing "completed" on every run but nothing on the receiving end was actually changing. I refreshed the dashboard four times thinking it was a display lag. It was not a display lag. The automations had Read-only permission scope the entire time, which means they could see my data but could not touch anything. The documentation does not mention this during setup. You find out after you have already built everything.
What Every Competing Article Gets Wrong About Sinkom
Every article on sinkom is basically the same article. Describe the architecture. List the features. Add a security paragraph. Mention smart homes. Done. Nobody ever tested anything.
Here is the core problem with how sinkom is typically described: the platform is modular, which means the components do not automatically connect and communicate with each other out of the box. The documentation describes the result of a correctly configured system. It does not describe the configuration steps you have to complete manually before that result is possible.
Every sinkom tutorial describes the destination. None of them describe the road, the wrong turns, or what happens when you take the default route.
The other consistent failure across competing articles is the audience mismatch. They write for someone who has never heard of the platform, so they spend 800 words explaining what IoT is. If you are reading this, you already know what IoT is. You want to know why your specific setup is not working.
How Sinkom Actually Works
Sinkom operates on three processing layers. Understanding what each layer can and cannot do on its own is the difference between a deployment that works and one that stalls silently for reasons that are genuinely difficult to debug.
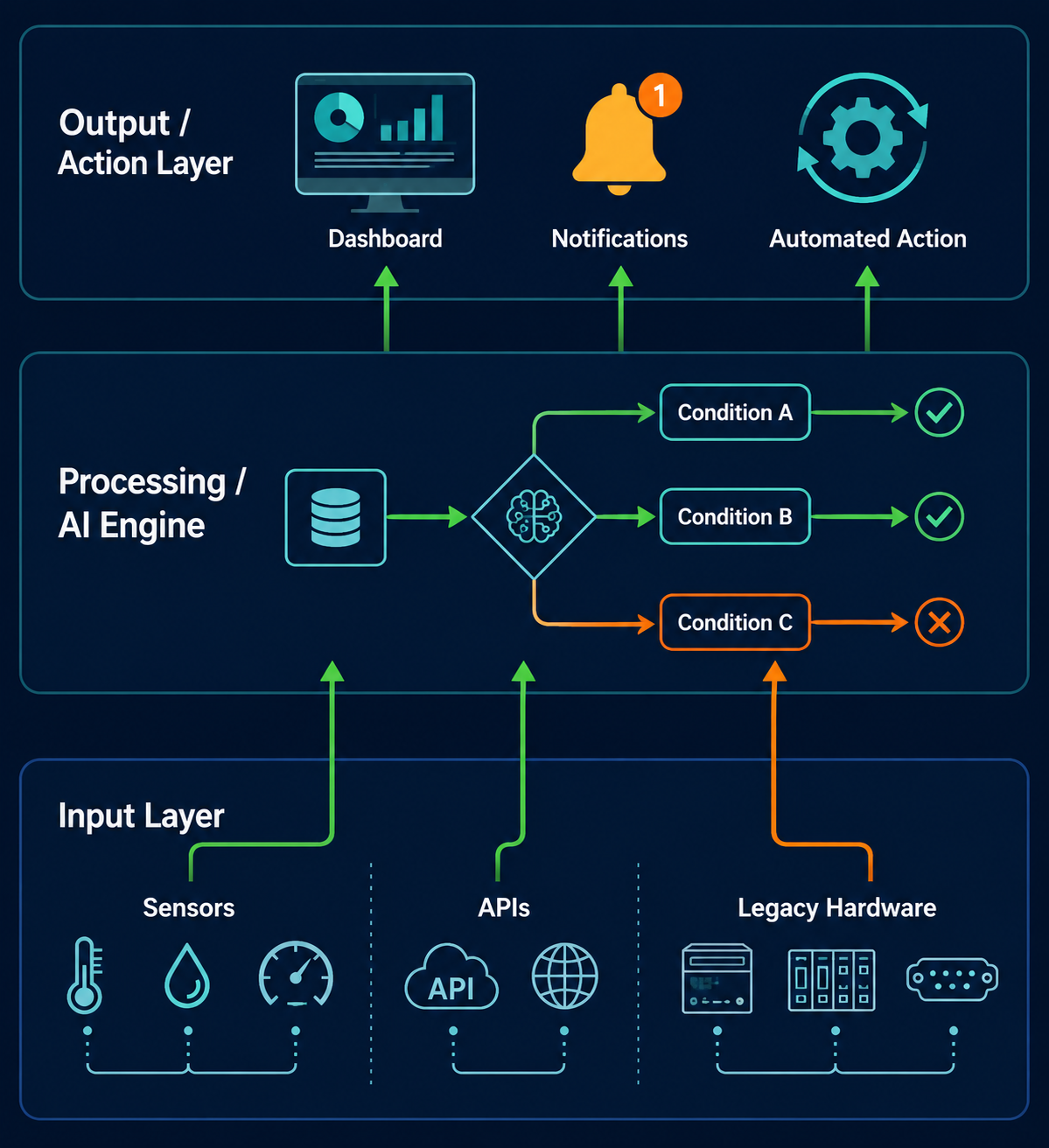
The Three Layers and What They Cannot Do on Their Own
The input layer collects raw data from devices, sensors, and connected external platforms. This is where most deployments fail first. When legacy hardware using older serial protocols sends raw unformatted data into the system, sinkom does not automatically decode it. The processing engine cannot interpret arbitrary data schemas. It expects structured input in a defined format. If your devices are sending raw strings instead of structured data, the packets get dropped silently. No error message. Just silence.
Do not follow any advice that tells you to let the system auto-detect your hardware configurations. That feature does not work the way the documentation implies. You must manually map your device payload schemas before connecting them to the processing layer.
The processing layer is the AI engine, and this needs a realistic description because competitors consistently oversell it. On a new account, the engine runs on default rule sets, not on learned intelligence. It requires two to three weeks of consistent data from connected sources before the pattern recognition produces reliable results. If you judge the platform's capabilities based on week-one behavior, you will underestimate it badly. If you expect it to make smart decisions on day one, you will be wrong.
The output layer handles automations, dashboard metrics, and alerts. This layer is fully configurable, but it has a reset behavior that no article mentions and that will cost you time if you do not know about it.
What the AI Engine Is Actually Doing With Your Data
The AI is not reading minds. It is matching patterns against thresholds. Smart, fast, and useful — but not magic, and definitely not useful on day one before it has any data to learn from. It runs classification logic against incoming data points, comparing them against rule sets that you can modify. Think of it as a fast pattern-matching engine with the ability to build a baseline model of your normal operational patterns over time.
This article covers why verifying what an AI tool actually does with your data matters before you connect it to your workflow: https://allblogsidea.com/blog/gramhir-pro-ai-verify-before-you-trust
The common advice is to connect every integration immediately and let the AI learn from all of it simultaneously. That approach fills your baseline model with mixed signals from the setup period, which means the system learns your configuration behavior rather than your actual operational patterns. Connect integrations one at a time. Give the system a week per integration before adding the next.
Where Sinkom Breaks in Real Deployments
Four specific failure points. Not vague "implementation challenges." Four things that cause the system to behave incorrectly, silently, in ways that take time to diagnose.
The Protocol Incompatibility Problem
The platform documentation states that sinkom provides communication across devices regardless of brand or network. That claim requires a significant qualification: it works across devices that are sending data in a format the integration layer recognizes. When you mix legacy hardware with modern smart sensors, the synchronization architecture stalls at the parsing stage.
Legacy devices using older serial protocols dump raw telemetry into the central module. The processing engine does not know what to do with it and drops the data. Your device shows as connected. Your logs show data transmissions. But the data never reaches the processing layer because the payload format was never mapped.
The fix requires a lightweight proxy script sitting between your legacy device and the sinkom input layer. The script translates raw hardware output into structured JSON before the data reaches the central module. This is a one-time configuration task, but it is a task that no tutorial mentions because the tutorials assume all your devices are modern and API-compliant.
The Zero-Trust Session Timeout No One Mentions
Sinkom's security architecture operates on a zero-trust model, which means every device connection is continuously re-verified rather than assumed to be safe after initial authentication. This is the right security approach. The implementation detail that breaks deployments is the default session Time-To-Live setting.
By default, the central hub requires an authenticated keep-alive signal from connected devices within a fixed window. If a device does not send that signal within the required interval, whether because of a brief network interruption, a hardware polling delay, or a temporary load spike, the hub silently removes that device from the authenticated pool. The device believes it is still connected and keeps sending data. The hub ignores the data completely. No alert fires. No error log entry appears in the standard view. The data simply stops flowing.
I caught this one by accident. I was checking a different metric on the dashboard and noticed the last updated timestamp on one of my device feeds had not changed in about two hours. The device was showing as connected on the hardware side. The sinkom panel also showed it as connected. The log showed zero error entries. It took me twenty minutes of comparing timestamps across different panels before I found that the session had been silently dropped and the hub was ignoring incoming data from that device entirely. The fix required going into the config file, not the dashboard, and the session TTL setting is not labeled in a way that makes it obvious what it controls.
The fix is in the core configuration file, not the dashboard. The web UI hides advanced timeout settings because the platform is designed around functional minimalism, which in practice means advanced settings are accessible via terminal or config file access only. You need to extend the session timeout limits to match your actual device polling intervals and define persistent connection certificates for your trusted local hardware.
Why Your Dashboard Resets After the First Connection
You customize your sinkom dashboard. You remove the default widgets, pin the metrics that matter, and arrange the layout to match your workflow. Then you connect a new integration. The dashboard reverts to the default layout.
This is not a bug. Sinkom treats each new integration as a potential new data source that could affect existing widget configurations, so it resets the dashboard layout to prevent widget errors. The logic makes sense architecturally. The fact that it happens without any warning does not make sense from a user experience perspective.
The fix is a Layout Lock setting under the Advanced tab in Dashboard Settings. It is not in the main settings menu. Enable it before customizing your dashboard, not after losing your layout for the first time. Once locked, new integrations add data to the system without resetting your configured layout.
The Hidden Setting That Overrides Everything You Configure
This is the section that no competing article covers, and it is the most common reason experienced users waste hours debugging a sinkom deployment that appears correctly configured.
On team and organization accounts, sinkom has an admin permission layer that sits above user-level and integration-level settings. This layer includes a Workspace Governance Mode setting that most account owners never encounter because it is configured at the organization level during initial account creation and is not visible in the standard settings menu.
Workspace Governance Mode has two states: Open and Governed. If your account was created with a business email domain, the default state is Governed. In Governed mode, the organization-level defaults override certain user-level configurations silently. This includes notification preferences, dashboard widget configurations, and integration permission scopes.
The most common reason sinkom behaves differently than expected has nothing to do with your configuration — it is the admin governance layer overriding everything you set.
If your settings keep reverting after you save them, this is the first place to check. Go to Organization Settings, select Workspace, and look at the Governance field. If it reads "Governed," any settings you change at the user level are subject to organization-level defaults. The fix is either to change the governance mode at the admin level or to have the account owner push updated organization defaults that match what you need.
This one took the longest to find because the symptom looked exactly like a user error. I kept changing a notification preference, saving it, confirming it was saved, then coming back an hour later to find it reverted. I went through support chat and got a response suggesting I clear cache and try a different browser. Clearing cache did nothing. Eventually I found a reference in a forum thread to the Workspace Governance setting, went to Organization Settings (not the regular settings page, a separate section), and found it was set to Governed mode. The organization-level defaults were overriding my user-level saves every time. Support had not mentioned this once.
Fixing the State File Wipe That Kills Your Learned Automations
This one appears two to three weeks after a successful deployment, which makes it particularly frustrating because by that point the system has built up useful pattern data and the automations are working well. Then you push a routine update or the server reboots. Two weeks of learned behavior, gone. The system wakes up from the restart with no memory of your setup. Starts learning from zero. Again.
The cause is straightforward. Sinkom's adaptive learning layers write their state files to a temporary cache directory by default. When a container resets, an update runs, or the server reboots, the temporary cache is cleared. The system loses its optimization history and starts pattern learning from scratch.
You need to tell the system to stop writing its memory to a location that gets wiped on every restart. The dashboard backup setting does not handle this. You have to do it in the config file directly. Map the state storage path to a persistent volume. This is not a setting in the dashboard. You need to update the environment variables in your configuration to point the state directory at a permanent database location, and you need to force a hard write to that location after every successful optimization cycle rather than relying on the automatic backup settings in the UI.
Do not assume the automatic backup feature handles this. The automatic backup covers user account settings and integration connections, not the adaptive state data. Those are treated as separate data types in the storage architecture.
Getting Real Value From Sinkom After Setup
Assuming the integration permissions are set correctly, the dashboard layout is locked, the governance mode is verified, and the state files are mapped to persistent storage. Now the platform works the way the brochure promised. Here is what to do before adding anyone else.
The Integration Connection Order That Saves an Hour of Debugging
Connect your data sources before you connect anything the system is supposed to act on. You would not install an alarm siren before you installed the motion sensors. Same logic here. Data sources first, action targets second, notification channels third.
Connecting action targets before data sources means the AI engine has no pattern baseline against which to trigger actions. Your automations will either fire constantly or never. The pattern model needs real operational data from your sources before it can make accurate decisions about when to trigger actions against your targets.
Lock Your Layout Before Sharing Access
The Layout Lock toggle described earlier is per-user by default. A new team member who does not know about it will have their layout reset the first time they connect an integration. Save everyone the frustration: go to admin settings and set Layout Lock as the default state for all new users in the organization. It takes thirty seconds and prevents a recurring complaint.
The sinkom deployment problems described in this article are not difficult to solve once you know they exist. The challenge is that none of the documentation describes them clearly, and no competing article covers them at all. Start by verifying your workspace governance mode before you debug anything else. Check your integration permission scopes before you assume an automation is broken. Lock your dashboard layout before you customize anything. Map your state files to persistent storage before your first server restart. Get those four things right and the system works exactly as advertised.
Frequently Asked Questions
Why does my sinkom device stop sending data after a few hours even though it shows connected?
The zero-trust session management is cutting the authenticated connection without alerting you. By default, the hub requires a cryptographic keep-alive signal from connected devices within a fixed interval. If the signal does not arrive, because of a brief network hiccup or a hardware polling delay, the hub silently drops the device from the authenticated pool and ignores its data. Fix the session timeout in the core configuration file, not the dashboard.
Why did my sinkom dashboard layout disappear after i connected a new integration?
Sinkom resets dashboard layouts when new integrations are added, to prevent widget errors from new data sources. There is a Layout Lock setting under the Advanced tab in Dashboard Settings. Enable it before customizing your dashboard. Once locked, new integrations will not reset your layout.
My sinkom automations show as triggered in the log but nothing actually happens: what is wrong?
Your integration is almost certainly set to Read-only permission scope. Connecting an integration and completing the API authorization does not automatically grant write access. Go to your connected tools list, open the integration, and change the permission tier from Read to Read and Write. Then re-save any automations that reference that integration.
Why do my sinkom settings keep reverting after i save them?
Check your workspace governance mode. If your organization account is in Governed mode (the default for business email signups), user-level settings are overridden by organization-level defaults silently. Go to Organization Settings, select Workspace, and check the Governance field. Either change the mode at admin level or have the account owner update the organization defaults.
My sinkom automations learned my patterns perfectly and then a server restart wiped everything: how do i prevent this?
The adaptive state files are written to a temporary cache directory by default. Any container reset or server restart clears that cache. You need to update your environment variables to map the state directory to a persistent storage volume. The automatic backup feature in the dashboard does not cover state files. It only backs up account settings and integration connections.
Can i get advanced sinkom functionality without paying for higher pricing tiers?
Yes, for specific use cases. The modular architecture means you can configure direct webhook integrations and custom payload parsers without needing a managed enterprise tier. Where the higher tiers genuinely earn their cost is in managed support for complex multi-system deployments and guaranteed uptime. For a small team that can handle their own configuration, the lower tiers cover the core functionality.

